
Il 2025 potrebbe sembrare l’inizio della fase discendente per lo sviluppo dei grandi modelli di linguaggio, ma Xiaomi ha appena dimostrato il contrario con MiMo, il suo primo modello open source dedicato al ragionamento avanzato. Con questo progetto, il gruppo inaugura ufficialmente il lavoro del nuovo Xiaomi Large Model Core Team e punta a colmare il divario tra pre-addestramento e post-addestramento, proponendo una struttura inedita per potenziare le capacità di pensiero dei modelli.
Un nuovo paradigma per il ragionamento AI
MiMo si concentra su una sfida chiave: come stimolare il potenziale del ragionamento in un modello LLM. In risposta a questo interrogativo, Xiaomi ha sviluppato una pipeline combinata di pre-training e post-training capace di migliorare l’inferenza sia nei compiti logici che in quelli computazionali.
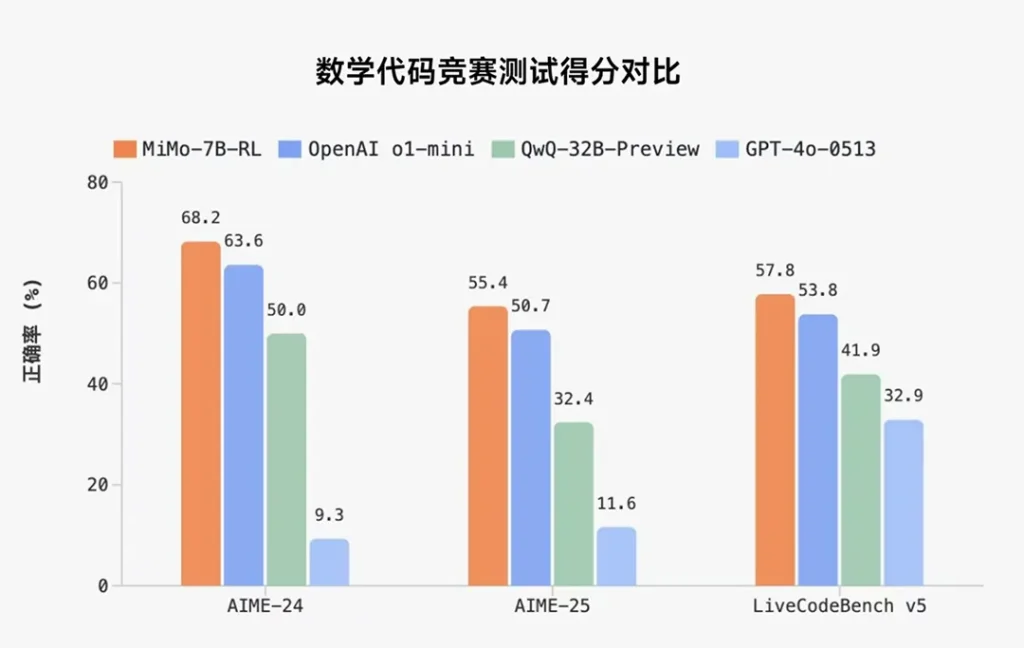
Nei benchmark pubblici dedicati al ragionamento matematico (AIME 24-25) e alla generazione di codice (LiveCodeBench v5), MiMo-7B ha superato sia o1-mini di OpenAI che QwQ-32B-Preview di Alibaba Qwen, pur avendo appena 7 miliardi di parametri. È una conferma del fatto che le dimensioni non sono tutto: conta il modo in cui si costruisce e allena un modello.
Potenziale superiore nel reinforcement learning
Nel panorama dell’apprendimento per rinforzo, MiMo-7B si dimostra più promettente dei modelli attualmente più usati per il fine-tuning in RL, come DeepSeek-R1-Distill-7B e Qwen2.5-32B. Utilizzando gli stessi dati, Xiaomi ha evidenziato come MiMo riesca a esprimere un potenziale di apprendimento superiore, in particolare nei settori della matematica e della programmazione.
Innovazioni nel pre-addestramento e nel fine-tuning
Nel pre-addestramento, MiMo ha integrato circa 200 miliardi di token orientati specificamente al ragionamento, con una progressione su tre fasi di difficoltà crescente per un totale di 25 trilioni di token addestrati. L’obiettivo non era la semplice esposizione a testi, ma una vera immersione nelle modalità del ragionamento umano e computazionale.
Nella fase di post-addestramento, Xiaomi ha introdotto due innovazioni chiave:
- una ricompensa graduata basata sulla difficoltà degli esercizi per affrontare la scarsità di segnali nei problemi complessi;
- la strategia Easy Data Re-Sampling per garantire una stabilità maggiore nell’addestramento.
A livello infrastrutturale, il nuovo sistema Seamless Rollout ha permesso di accelerare di oltre il doppio i tempi di addestramento e verifica nei task di reinforcement learning.
Tutto open source, su HuggingFace
Xiaomi ha reso disponibile l’intera serie MiMo-7B su HuggingFace, insieme al rapporto tecnico completo, pubblicato su GitHub:
📁 MiMo su HuggingFace
📄 MiMo Technical Report
Con questa apertura, Xiaomi mira a stimolare la ricerca e la collaborazione su modelli di ragionamento più efficienti, ponendosi come un attore rilevante nel panorama degli LLM, pur mantenendo un approccio pragmatico e orientato all’innovazione sostenibile.
Oltre il 2025, con i piedi per terra e lo sguardo sull’AGI
Xiaomi dichiara di essere consapevole che l’AGI è ancora lontana, ma con MiMo desidera partecipare attivamente alla sua costruzione. Non inseguendo hype, ma affrontando problemi concreti, come l’ottimizzazione del ragionamento attraverso pipeline di apprendimento più efficaci.
Aiutaci a crescere: lasciaci un like :)