

Lunedì 20 ottobre 2025, una vasta interruzione ha colpito Amazon Web Services, evento che ha paralizzato per almeno quattro ore migliaia di piattaforme in tutto il mondo. Dalle prime analisi, la causa sarebbe legata a un malfunzionamento interno dei sistemi DNS nella regione US-EAST-1, in Virginia, la stessa dove negli anni scorsi si sono concentrati altri incidenti critici per l’infrastruttura del colosso di Seattle.
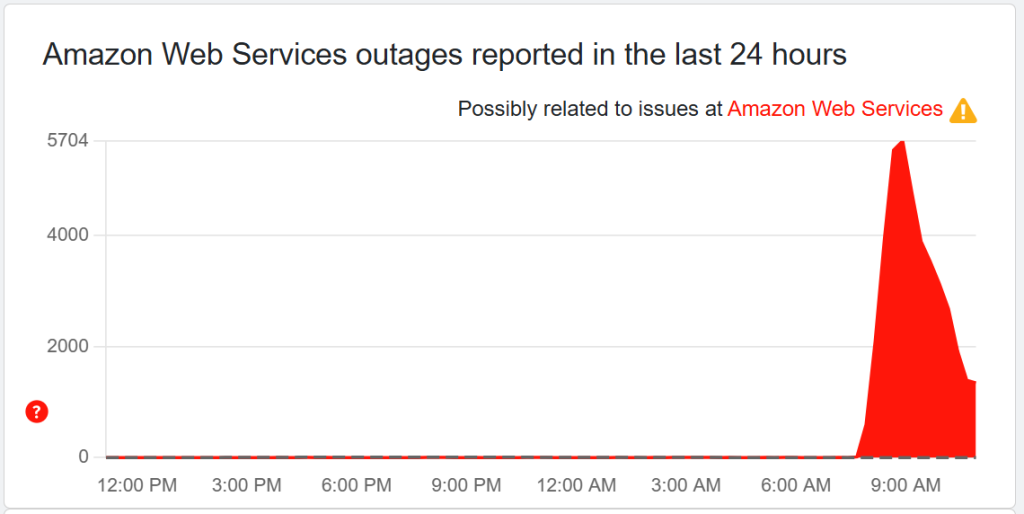
Secondo un portavoce di AWS, “alcuni servizi hanno registrato tassi di errore elevati e latenze anomale”, con un impatto che ha coinvolto strumenti di uso quotidiano come Snapchat, Duolingo, Fortnite e Zoom, oltre a numerosi portali bancari e sistemi di pagamento in Europa e Stati Uniti. L’interruzione, durata in media quattro ore, ha mostrato quanto l’economia digitale globale dipenda da un numero ristretto di nodi fisici.
La causa: un guasto interno, non un attacco
Come confermato dal ricercatore senior Aras Nazarovas di Cybernews, il disservizio è stato provocato da “guasti DNS interni presso Amazon Web Services nella regione US-EAST-1”. Problemi analoghi si erano già verificati in passato e sono spesso dovuti a “configurazioni errate o aggiornamenti mal gestiti, oltre a un monitoraggio insufficiente delle scadenze di certificati e parametri di rete”.
Le prime verifiche non indicano alcuna violazione della sicurezza o accesso non autorizzato, ma la disponibilità ridotta di risorse per i clienti AWS rientra comunque nella definizione di incidente informatico, anche in assenza di un attore malevolo.
Effetti a catena e rischio sistemico
Un singolo malfunzionamento in una delle regioni più utilizzate di AWS ha generato interruzioni diffuse in settori tra loro distanti. Le aziende che si affidano interamente a una sola infrastruttura cloud hanno sperimentato ritardi nei servizi, perdita temporanea di accesso ai dati e malfunzionamenti delle applicazioni.
L’episodio conferma una vulnerabilità strutturale: la concentrazione del traffico globale in poche regioni cloud. La US-EAST-1, per motivi storici e tecnici, è quella più trafficata e spesso funge da nodo centrale per i sistemi di bilanciamento e autenticazione. Quando si blocca, il resto della rete vacilla.
Secondo gli esperti, le conseguenze più gravi si registrano nei settori a infrastruttura critica, dove anche pochi minuti di inattività possono compromettere continuità operativa e sicurezza dei dati.
La lezione per le aziende
Nazarovas sottolinea la necessità di disporre di un Piano di Disaster Recovery che includa non solo la ridondanza dei dati, ma anche canali alternativi di comunicazione: “In caso di interruzioni di questo tipo, è fondamentale poter contare su app, chiamate o sistemi radio esterni per coordinare il ripristino”.
L’incidente offre l’occasione per ripensare la gestione della resilienza digitale. Le aziende dovrebbero:
– diversificare i provider o le regioni cloud per evitare punti di fallimento unici;
– automatizzare il monitoraggio di certificati e configurazioni DNS;
– testare periodicamente le procedure di failover e comunicazione d’emergenza.
Oltre l’incidente
Amazon non è nuova a eventi di questo tipo. Interruzioni nella stessa regione si erano già verificate nel 2021 e nel 2023, sempre per problemi di rete o errori interni. Ogni volta, il ripristino è avvenuto nel giro di poche ore, ma le ripercussioni su scala globale sono state immediate.

Aiutaci a crescere: lasciaci un like :)